< See latest news & posts
Done in 60 seconds: We’re obsessed with cluster setup time, so you don’t have to be.
TL;DR
- Our goal is to create single node clusters in your cloud account in under 60 seconds.
- Achieving this requires us to question every detail, and needs constant refinement.
- We built a custom release system to avoid 10-15 seconds of
apt-get update. - We’re using official Ubuntu LTS cloud images for the fastest consistent boot times.
- Our per-cluster serverless CA solution speeds up certificate issuance.
- We built a provisioner which makes direct API calls. No CloudFormation/Terraform.
- Our etcd alternative, Netsy, allows us to quickly boot dynamic snapshots of cluster state.
You’re a dev with a brilliant idea.
Thanks to LLMs, you’re building things faster than ever, and you’re ready to deploy.
Then reality hits; even with a great infrastructure template, waiting for container clusters to provision is like trying to download Xcode on airplane wi-fi. Time for a coffee break.
Sound familiar? You’re not alone.
You can only take so many coffee breaks
Cloud infrastructure providers like to talk about “enterprise-grade solutions” and “comprehensive toolchains.”
What they don’t mention is the complexity tax you’ll pay, and the absolute-time sink it’s going to be.
Not just in reading wordy manuals, dealing with the cognitive load of high risk decisions, and learning proprietary tools.
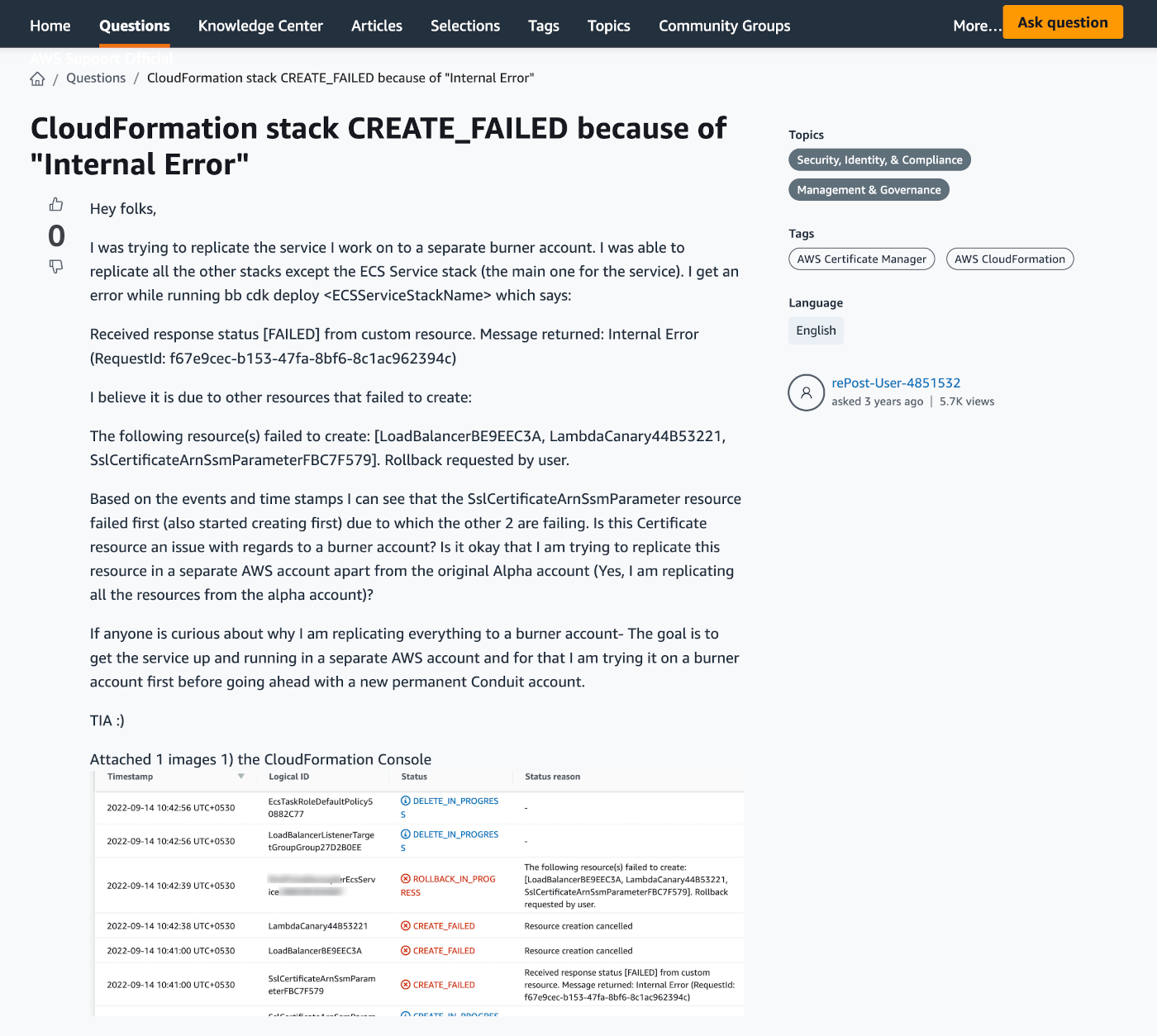
It’s also the 15-minute configuration-as-code deployments that only result in a CREATE_FAILED, or the third-party dependencies that chain you to someone else’s timeline.
These aren’t features. They’re friction. And friction disrupts flow.
There has to be a better way
We want to make the best developer experience for infrastructure. It’s what gets us out of bed in the morning. That, and young kids.
As a developer, your time is precious. You shouldn’t have to become an infrastructure archaeologist, deciphering ancient documentation manuals just to spin up a cluster.
You don’t want to have to explain to your product manager why “it’s just infrastructure” took longer than building the actual feature.
You deserve tools that work as fast as possible.
And you shouldn’t compromise to get it; Nadrama runs containers in your own cloud account, built on Open Source.
It turns out, making things fast is hard
When we started last year, we set ourselves an optimistic and possibly impossible goal: clusters that provision in under one minute.
Not “15 minutes”. Not “eventually”. Done in 60 seconds, like if Nicolas Cage and Angelina Jolie fell in love with DevOps.

This wasn’t just about being fast for the sake of it. It was about respecting your flow state, your deadlines, and frankly, your sanity.
And it’s about craft. Because honestly, we’ve hit our target multiple times, and then there’s always something that regresses things back off target.
So it’s not just an initial goal, but an ongoing one. It’s a constant challenge, but one we’re up for, and constantly monitoring and striving for.
Every second counts, and details matter
Achieving sub-minute provisioning meant questioning everything.
VM boots will happen not just on cluster creation, but any time you scale your cluster, or rotate nodes using expiry - so every second truly matters here.
Operating System? We tried using a container OS for fast boot times. It turns out, Ubuntu would boot ~1 second slower on average, but machines would provision faster when using official cloud provider machine images, likely due to a higher number of cache hits.
The same goes for custom machine images. So now we’re using the official Ubuntu LTS images.
Then we noticed that apt-get update was stealing precious seconds at boot time, often taking 10-15 seconds even when connecting to region-specific mirrors.
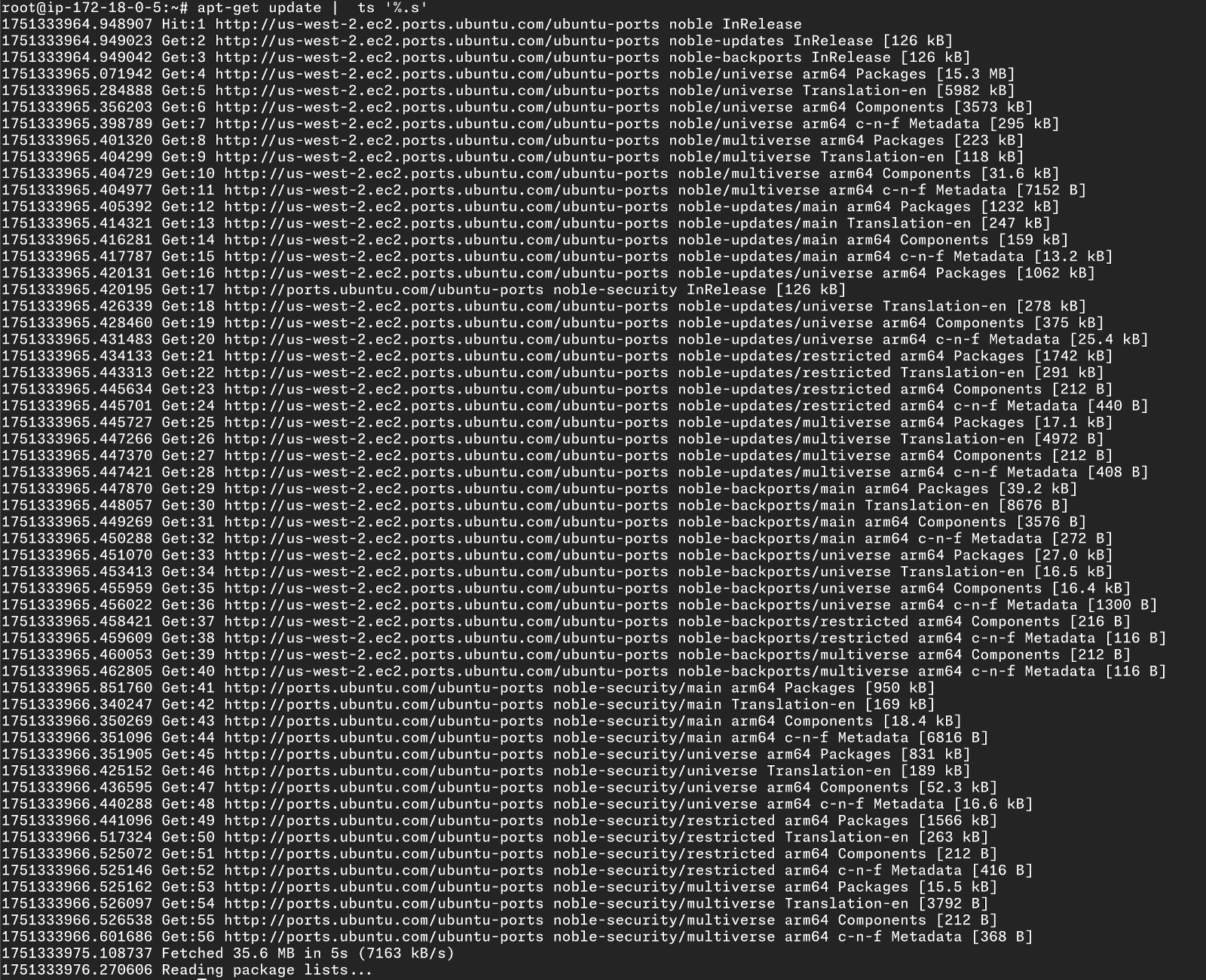
So we built our own system for downloading and installing the required binaries, which leverages HTTP/2 with request multiplexing.
CloudFormation or Terraform are fantastic tools. But even a single node cluster needs over 30 resources to be provisioned, and that would simply take too long.
So we created our own provisioning system that talks directly to cloud provider APIs. Less abstraction, more control, faster results.
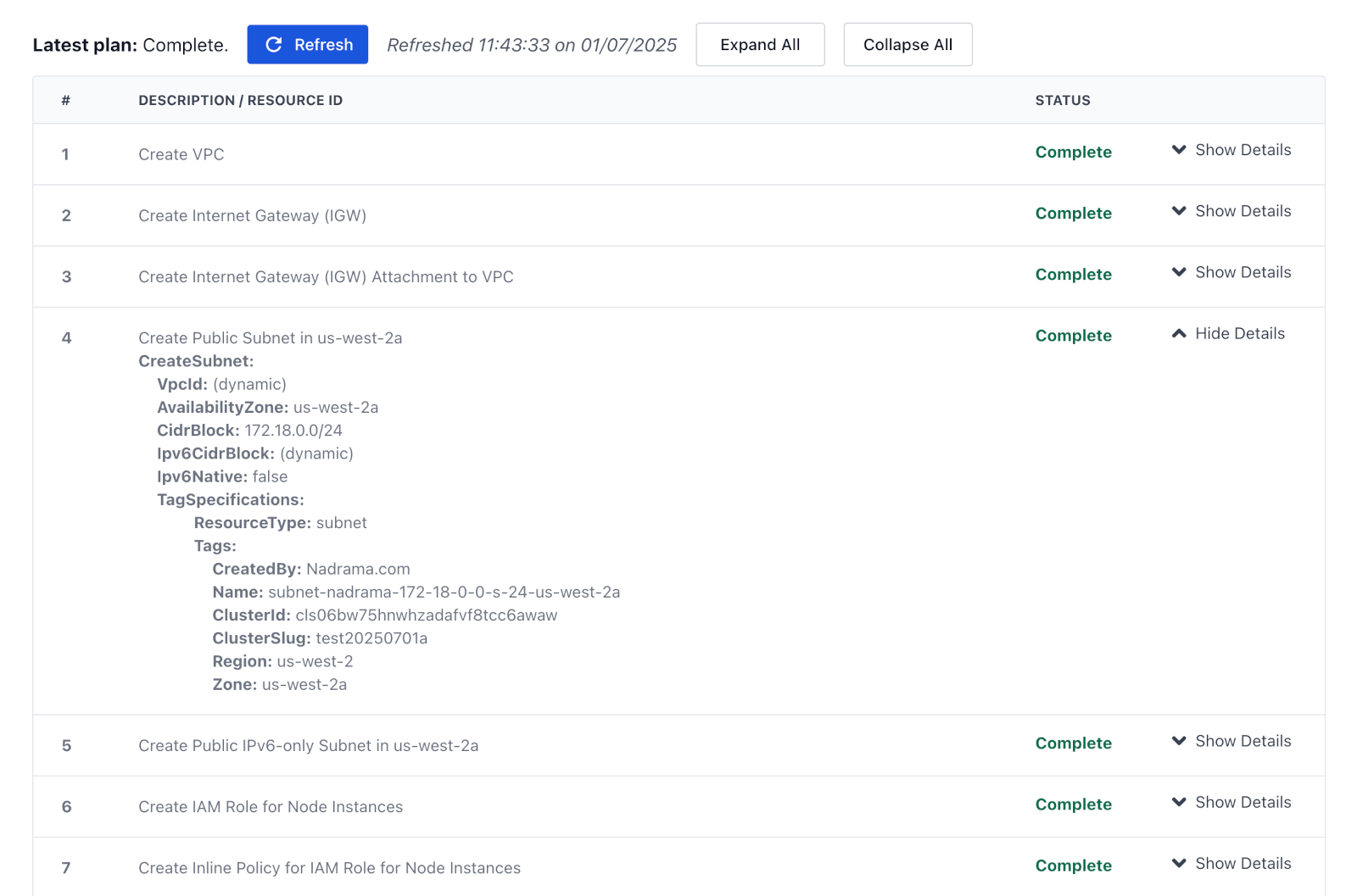
It wasn’t easy to build a fast and reliable provisioner; we had to build in state tracking, the ability to wait for dependencies to provision, and handling retries with exponential backoffs.
Typically, container platforms want you to set up or use a separate image registry. But you just want to deploy your app. So we built a registry into every cluster by default, with images stored in low cost object storage like S3.
We even created a per-cluster serverless CA solution. Because each cluster needs a bunch of certificates, and we didn’t want you waiting on those to be issued either - it all happens in less than a second.
The final piece was to be able to snapshot initial cluster state and quickly provision it using our etcd alternative, Netsy. You can’t just snapshot the same state across every cluster, so our solution uses a combination of static and dynamically generated data.
Ultimately, each decision was driven by one question: “How do we make this faster, to save developers time?”. Because it doesn’t make sense for the entire industry to be reading the same set of docs, and doing the same set of manual steps, when it could just be automated.
Minimal Infrastructure, Maximum Impact
The best infrastructure is the infrastructure you don’t need, and the second best is the infrastructure you don’t have to think about.
Every component we didn’t need was one less thing to slow you down, one less thing to break, one less thing to explain to your team.
We couldn’t remove everything, but we’re running things as light as possible, and continuously improving our design. And we more than welcome your feedback!
The Result: Ship your apps to production, faster
With a Nadrama cluster provisioning in under 60 seconds, you can move faster, and you can focus on shipping your apps and containers.
Don’t sign up for vendor lock-in or infrastructure complexity.
Use Nadrama. Run a single node cluster in your own cloud account, in less than 60 seconds. It’s free to start - sign up here.
Published: .