< See latest news & posts
Introducing Nstance: Nadrama’s VM auto-scaler
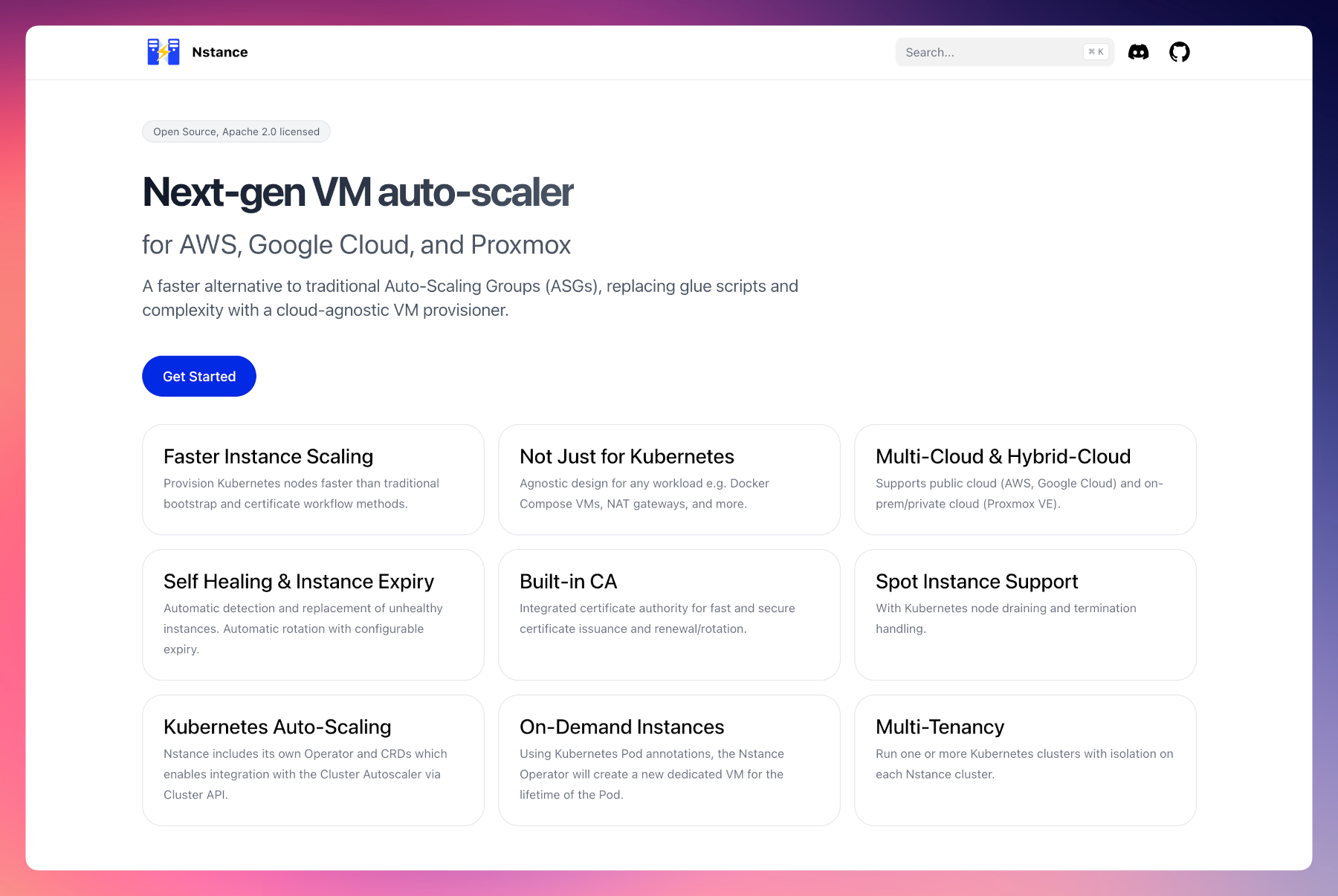
TL;DR
- Nstance is a new Apache 2.0 licensed VM auto-scaling system which can be used for Kubernetes clusters, CI build servers, and more.
- It provides fast and predictable auto-scaling of VMs across public cloud (AWS, Google Cloud) and on-prem/private cloud (Proxmox).
- Nstance’s architecture enables unified configuration in multi-cloud and hybrid-cloud deployments.
- Features include auto-scaling, health monitoring, instance rotation/expiry, TLS certificate management with a built-in CA, spot instance support, scale-to-zero support, on-demand VMs for Kubernetes Pods, and multi-tenancy.
- Please show your support by starring the Nstance GitHub repository!
Today, Nadrama is launching Nstance, a new type of VM auto-scaler, released under the Apache 2.0 license.
Nstance is available on GitHub today, with extensive documentation at its dedicated website: nstance.dev.
This release is another milestone in the Nadrama commitment to going all-in on Open Source. Over the past few months, Nadrama has released Netsy (an S3-backed etcd alternative), Easy OIDC (a straightforward OIDC server for Kubernetes), and Prebake (turning bare clusters into developer platforms). Nstance is the next piece of the puzzle: how the underlying VM infrastructure is orchestrated.
If you’re interested in why Nstance was built and the design decisions behind it, read on!
The problem with current approaches
If you’ve ever managed Kubernetes clusters or VM infrastructure in production, you’ve likely felt these pain points:
Auto-scaling is slow and opaque
When an Auto-Scaling Group (ASG) needs to replace a VM instance, there’s little visibility into when the replacement will actually arrive. It typically takes tens of seconds just for a new VM to be created. During incidents, this lack of predictability is stressful. Delays in instance replacement mean real downtime for customers.
And for Proxmox VE users, there is no native support for auto-scaling VMs at all.
Infrastructure bootstrapping is fragile
Conventional approaches to bootstrapping new Kubernetes clusters often rely on a “management cluster” (via Cluster API or similar) that deploys and manages each “workload cluster”.
But what happens when you upgrade and break your management cluster, and simultaneously need to respond to an incident in a workload cluster? This approach creates a single point of failure for all of your infrastructure.
Security boundaries are too loose
In many setups, workloads running inside a Kubernetes cluster have access to the cloud provider credentials used for provisioning its infrastructure. If a container is compromised, an attacker could potentially interact with your cloud provider APIs — view sensitive data and secrets, or create/modify/delete infrastructure.
”Cattle not pets” is still too hard
The idea of treating servers as disposable has been around since 2011-2012, but implementing it properly remains difficult with conventional tooling, particularly if it’s the last running VM in a cluster that you’re deleting.
Multi-cloud is painful
Managed Kubernetes offerings differ significantly across clouds, and there’s huge complexity in attempting to link them together.
Major public/private cloud providers all use the same underlying primitives: VPCs, subnets, VMs, object storage. So why can’t you deploy clusters in multi-cloud and hybrid-cloud configurations? And in a way that the in-cluster configuration remains cloud-agnostic and portable?
How Nstance solves this
Nstance takes a fundamentally different approach to VM provisioning and auto-scaling, by cleanly separating concerns and keeping things simple.
Four focused components
Nstance consists of four components, each with a single responsibility:
- Server — Runs per availability zone “shard”. Manages instances, issues TLS certificates, and is the only component that talks to cloud provider APIs.
- Agent — Runs on every VM and connects to the leading Server for its shard. Handles instance registration, key generation, certificate retrieval, and health reporting.
- Operator — A Kubernetes controller that syncs Cluster API resources with each Nstance Server, and enables integration with the Kubernetes Cluster Autoscaler via Cluster API.
- Admin — A CLI and HTTP API for admin tasks and for non-Kubernetes use cases.
This separation means no workload running inside the cluster needs cloud provider API access. Nstance Server is the only component with that privilege, and its permissions are scoped to the minimum needed for VM management.
Fast failure detection
When a VM receives a shutdown signal and sends it to the Nstance Agent, it immediately reports it to the Nstance Server. The server checks with the cloud provider API, and starts instance replacement in milliseconds — not seconds or minutes.
Built-in features for production
Replacing incumbent solutions requires a comprehensive featureset. Nstance ships with a robust set of features designed to reduce the gap on production readiness to zero.
- Auto-Scaling — Automatically reconciles instance group configuration to maintain and scale to desired capacity.
- Health Monitoring — Agent health reports with unhealthy node detection and automatic instance replacement.
- Spot Instances — Automatic detection and handling of spot and preemptible instance termination notices.
- TLS Certificates — Certificate issuance, renewal, and management for instances, with the CA key living outside the Kubernetes cluster.
- Instance Expiry — Automatic instance rotation based on configurable age limits for compliance and security.
- Load Balancers — Automatic registration and deregistration of instances with cloud provider load balancers.
- On-Demand Nodes — Provisioning individual instances on-demand via Pod annotations for specific workload requirements.
- Multi-Tenancy — Multiple Kubernetes clusters can run on a single Nstance cluster with tenant isolation.
- Subnet Pools — Logical subnet pool system that maps human-readable names to provider-specific subnet IDs, making group configurations portable across clouds and environments.
- Scale-to-Zero — Nstance Server runs on the smallest possible VM (often cheaper than a single IPv4 address), and uses object storage for state persistence, enabling true scale-to-zero for your cluster VMs.
Multi-cloud by design
Nstance is designed for easy addition of new cloud providers and on-premise support through standardised provider interfaces. Based on learnings from the Nadrama public beta of single-node clusters in AWS (now closed), Nstance launches today with support for AWS, Google Cloud, and Proxmox VE.
Subnet Pools make configuration portable. For example, groups synced across an Nstance shard in AWS and in Google Cloud can both reference subnets by name, with cloud-specific mappings handled in each shard’s config via OpenTofu/Terraform.
Architecture at a glance
Nstance Server is designed to be vertically scaled. A single server can handle hundreds of nodes on a t4g.nano on AWS. For most use cases, one Nstance Server per availability zone is sufficient. Leader election provides hot standby capability for fast failover.
Each server attaches to a fixed IP/network interface, removing the need for a load balancer per zone. The HTTP health endpoint ensures ASGs don’t consider instances healthy until fully initialised, and object storage handles state persistence — making the entire setup durable and simple to operate.
Part of the Nadrama Open Source ecosystem
Nstance joins a growing family of Nadrama Open Source projects, each solving a specific challenge in the Kubernetes ecosystem:
- Netsy — S3-backed etcd alternative for Kubernetes.
- Easy OIDC — Straightforward OIDC server for Kubernetes authentication.
- Prebake — Turn bare Kubernetes clusters into developer platforms.
It also builds upon two existing Nadrama Open Source packages: puidv7 for prefixed instance UUID’s, and s3lect for leader election using object storage.
Together, these projects form the foundation of the new Open Source version of the Nadrama PaaS, expected to launch in the coming months.
Get started
Check out the Nstance documentation at nstance.dev, explore the code on GitHub, and share your feedback!
Please show your support by starring the Nstance GitHub repository.
If you’d like to connect, provide feedback, or get early access to the Nadrama PaaS, please join the Discord community. Thanks for reading!
Published: .